Раздел “Схема”¶
Раздел предназначен для просмотра и редактирования схемы данных.
Warning
Перед внесением каких-либо изменений в схему сделайте резервную копию базы данных, а также убедитесь, что пользователи сейчас не работают с системой.
Схема данных представлена в виде дерева.
В отдельных ветвях содержатся пользовательские Таблицы, Процедуры, Функции, Миграции и Библиотеки.

Каждая из этих ветвей содержит объекты соответствующего типа (таблицы/ процедуры/ функции/ миграции/ библиотеки), разделенные на группы (группа задается в свойстве “Группа” самого объекта).
Изначально объект не входит ни в одну группу.

Действия, доступные через контекстное меню (вызывается щелчком правой кнопкой мыши по элементу дерева):
Действие |
Команда в контекстном меню |
|---|---|
| Добавить колонку в выделенную таблицу | Добавить физическую колонку |
| Добавить ссылочную колонку | Добавить комплексную колонку |
| Добавить первичный ключ | Добавить первичный ключ |
| Добавить уникальный ключ | Добавить уникальный ключ |
| Добавить индекс | Добавить индекс |
| Добавить таблицу | Добавить таблицу |
| Добавить библиотеку | Добавить библиотеку |
| Добавить миграцию | Добавить миграцию |
| Добавить хранимую процедуру | Добавить процедуру |
| Добавить функцию | Добавить функцию |
| Удалить выделенный объект | Удалить |
Поиск какого-либо объекта можно выполнить, введя часть названия в поисковое поле:

Импорт схемы данных/библиотеки из файла¶
Для того, чтобы импортировать (“накатить”) новую схему данных из файлов, нажмите кнопку Импорт - Файл схемы…

Появится диалог выбора основного файла структуры БД. Такой файл имеет расширение *.tsd и обычно называется tessa.tsd. Выбираем файл, откроется окно с информацией по связанным со схемой библиотекам:

Нажав на Х слева от названия библиотеки её можно исключить из импортируемой схемы. Для подключения дополнительных библиотек надо нажать на соответствующую кнопку и в файловой системе выбрать папки с файлами библиотек, имеющими расширение *.tsp.
После нажатия на кнопку ОК система определит, изменяет ли новая схема БД текущую, и при наличии изменений отобразит их список в соответствующем диалоге.

Нажмите кнопку “Сохранить”. Система начнет применять изменения одно за другим. Применяемое изменение подсвечивается желтым. Успешно примененное изменение подсвечивается зеленым цветом. Дождитесь выполнения всех шагов и нажмите кнопку “Закрыть”.

Note
Если при обновлении произошла ошибка, то применение изменений останавливается, и ошибочный шаг подсвечивается красным. Двойной клик по этому шагу покажет диалог с детальным описанием ошибки.
Если требуется к текущей схеме данных импортировать библиотеки, следует воспользоваться кнопкой Импорт - Файлы библиотек…. Появится диалог выбора папок. Необходимо выбрать папку, в которой есть файлы библиотек *.tsp, и далее система выдаст список изменений, которые будут внесены в схему данных, для подтверждения сохранения нажать “Сохранить”.
Сохранение схемы данных¶
После внесения каких-либо изменений для сохранения схемы непосредственно в базу данных необходимо нажать на Сохранить всё:
В появившемся диалоговом окне будет отображен список изменений, для сохранения нажмите “Сохранить”:

В случае, если изменений в схеме данных не будет найдено, в диалоговом окне будет выведено соответствующее сообщение:

Создание таблиц¶
Для создания таблицы вызовите контекстное меню (щелкнув правой кнопкой мыши по узлу Таблицы) и выберите пункт “Добавить таблицу”:

Найдите новую таблицу. Она создалась с именем Table в разделе (без группы):

Задайте параметры таблицы:
-
Название – название таблицы (название таблицы используется при создании карточек и представлений, поэтому его изменение нежелательно);
-
Группа – группа таблицы нужна для удобства работы со схемой данных (таблица будет отображаться в другой группе сразу после изменения поля);
-
Описание – описание предназначения таблицы;
-
Библиотека - библиотека, в которой будет храниться данная таблица, по умолчанию -
Default; -
Используется для типа - тип объекта, с которым ассоциированы данные в создаваемой таблице. Указывается в зависимости от типа объекта системы, для которого предназначена таблица:
-
Не указан – тип не определён;
-
Карточки;
-
Задания;
-
Файлы;
-
-
Тип секции – тип данных, хранимых в таблице:
-
Перечисление;
-
Строковая – одиночные записи. На один объект (карточка, задание и т.п.) одна запись в таблице;
-
Коллекционная – коллекционные записи. На один объект может приходиться несколько записей в таблице;
-
Иерархическая – иерархические записи. Тоже самое, что и коллекционные, но с поддержкой иерархии записей;
-
-
Виртуальная – является ли таблица виртуальной. Виртуальная таблица описана в схеме данных, но физически отсутствует в базе данных.
Important
Для упрощения процесса обновления на новые версии платформы крайне желательно все объекты схемы данных (такие как таблицы, колонки и т.п.), добавляемые и изменяемые в рамках проектного решения, сохранять в отдельной библиотеке. Подробнее библиотеки рассмотрены в разделе Создание библиотек.
Добавьте в таблицу необходимые колонки, ключи и индексы. Для этого вызовите контекстное меню (кликнув по таблице правой кнопкой мыши) и выберите нужный пункт, либо используйте горячие клавиши (см. выше).
После того, как настройка таблицы будет завершена, необходимо её сохранить. Для сохранения нажмите [Ctrl]+[S], затем в появившемся диалоговом окне со списком изменений нажмите “Сохранить”:

Создание колонок¶
Колонки используются для задания значений атрибутов схемы и представлены в таблицах как столбцы. Создать колонку можно двух типов: физическую и комплексную.
Физическая колонка хранит значения, такие как номера или строки, в то время как комплексная колонка ссылается на значения и колонки других таблиц, может содержать произвольный тип и необходима для поддержания ссылочной целостности базы данных.
При создании физических и комплексных колонок следует внимательно следить за типом значений, которые будут храниться в них. Так, тип целочисленных значений Int16, в отличие от Int32, требует меньше памяти для хранения, однако в нем нельзя хранить слишком большие числа.
Добавление колонки осуществляется при помощи контекстного меню:

Таблица с доступными типами данных для колонок схемы¶
| Название | Описание и параметр (в скобках) | Типы в SQL и .NET | Тип в карточках | Контролы в карточках |
|---|---|---|---|---|
| AnsiString | Строка, закодированная в текущей кодовой странице для базы данных MSSQL, для Postgres используется кодировка UTF-8 аналогично типу String. (Max) - строка неограниченной длины (до 2 Гб текста) |
MSSQL: varchar Postgres: text .NET: string |
string | Нумератор Строка Текст Текст с форматированием |
| String | Строка, закодированная в UTF-8. В контролах можно использовать символы Unicode: иероглифы, иностранные буквы, финансовые и математические обозначения и т.д. (Max) - строка неограниченной длины (до 2 Гб текста) | MSSQL: nvarchar Postgres: text .NET: string |
string | Нумератор Строка Текст Текст с форматированием |
| Int16 | Целочисленный тип данных. Размер - 16 бит. Этого достаточно для хранения значений не больше 32 767 | MSSQL: smallint Postgres: smallint .NET: short |
int | Выбор цвета Строка Целое число |
| Int32 | Целочисленный тип данных. Размер - 32 бита. Этого достаточно для хранения значений не больше 2 147 483 647 | MSSQL: int Postgres: integer .NET: int |
int | Выбор цвета Нумератор Строка Целое число |
| Int64 | Целочисленный тип данных. Размер - 64 бита. Подходит для хранения значений, которые выходят за диапазоны типов int16 и int32 |
MSSQL: bigint Postgres: bigint .NET: long |
int | Нумератор Строка Целое число |
| Double | Вещественный тип данных, число с плавающей запятой размером 8 байт | MSSQL: real Postgres: double precision .NET: double |
double | Вещественное число Строка |
| Currency | 64-битные целые числа, масштабированные в 10 000 раз для представления числа с фиксированным десятичным разделителем (15 цифр слева от него и 4 цифры справа) | MSSQL: money Postgres: money .NET: decimal |
decimal | Десятичное число Строка |
| Decimal | Содержит 128-разрядные (16-байтные) значения со знаком, представляющие 12-байтные целые числа с переменной степенью, кратной 10. Коэффициент масштабирования определяет количество цифр справа от десятичной запятой. Он находится в диапазоне от 0 до 28. (0..29, 0..28) - первое число означает число знаков до запятой, второе - после. Сумма значений в скобках не должна превышать 29 | MSSQL: decimal Postgres: decimal .NET: decimal |
decimal | Десятичное число Строка |
| Time | Формат времени без даты, занимает от 3 до 5 байт памяти, точность определяется пользователем | MSSQL: time Postgres: time without timezone .NET: time |
time | Дата и время Строка |
| Date | Формат даты без времени, занимает 3 байта и предназначен для хранения даты диапазоном от 01.01.0001 до 31.12.9999 | MSSQL: date Postgres: date .NET: short |
date | Дата и время Строка |
| Datetime | Стандартный тип данных для хранения даты и времени. Занимает в памяти 8 бит: 4 для хранения даты и 4 - для хранения времени | MSSQL: datetime Postgres: timestamp without timezone .NET: DateTime |
datetime | Дата и время Строка |
| Datetime 2 | Формат времени-даты, представленный SQL Server 2008. В отличие от datetime, часть с датой представляют три последних бита |
MSSQL: datetime2 Postgres: timestamp without timezone .NET: DateTime2 |
datetime | Дата и время Строка |
| DatetimeOffset | Тип данных, который, помимо даты и времени, хранит также информацию о смещении, по которому было установлено текущее время | MSSQL: datetimeoffset Postgres: timestamp with timezone .NET: DateTimeOffset |
datetimeoffset | Дата и время Строка |
| Boolean | Логический тип данных | MSSQL: bit Postgres: boolean.NET: bool |
bool | Флажок Строка |
| Binary | Бинарные данные. (Max) - строка неограниченной длины. Вместо Max можно указать максимальную длину строки от 1 до 8000 | MSSQL: varbinary Postgres: bytea .NET: byte[] |
binary | Строка |
| Guid | Тип, предназначенный для хранения уникальных идентификаторов UUID/Guid |
MSSQL: uniqueidentifier Postgres: uuid .NET: Guid |
guid | Строка |
| Xml | Содержит код в xml-разметке | MSSQL: xml Postgres: xml .NET: sqlxml |
xml | Нумератор Строка Текст Текст с форматированием |
| Json | Содержит точную копию введённых JSON-данных с сохранением форматирования | MSSQL: nvarchar(max) Postgres: json .NET: string |
json | Нумератор Строка Текст Текст с форматированием |
| BinaryJson | Содержит JSON-данные, хранящиеся в бинарном виде, без сохранения форматирования. Поддерживает индексацию | MSSQL: nvarchar(max) Postgres: jsonb .NET: string |
binaryjson | Нумератор Строка Текст Текст с форматированием |
| Reference | Тип, доcтупный только комплексным колонкам | Сохраняются типы колонок таблицы, на которую ссылается | reference | Ссылка |
При использовании типов данных следует учесть следующие моменты:
-
Не используйте типы
ByteиSByte, в Postgres есть двухбайтовый аналогint2, который будет использоваться, что приведёт к разному поведению при загрузке типов из базы в серверном коде (тип данныхshortилиbyte). -
Не используйте беззнаковые типы
UInt16,UInt32,UInt64, поскольку в Postgres вместо них будут использоваться знаковые. -
Не используйте
Single, поскольку это число с плавающей запятой и низкой точностью, что приводит к потерям точности при операциях со значением, при этом размер поля в байтах незначительно ниже, чемDouble. -
Используйте
DecimalвместоDoubleдля хранения денежных сумм, поскольку эти типы не имеют потерь точности при операциях. Например, типDecimal(18,2)является достаточным для надёжного хранения любых сумм в большинстве случаев. -
Тип данных
Currencyсоответствует типуmoneyв MSSQL и в PostgreSQL, причём для каждой СУБД максимальные значения и точность отличаются. ИспользуйтеDecimal, чтобы однозначно указать эти параметры.
Пример создания таблицы для хранения значений перечисления¶
Данная таблица нужна для хранения списка записей, из которых потом в поле карточки пользователь сможет выбрать какую-либо одну.
Шаг 1: Создайте таблицу с Используется для типа - Не указан и Тип секции - Перечисление:

Шаг 2: Добавьте в таблицу колонку с первичным ключом (ID), колонку с названием элементов перечисления и другие необходимые поля:

Шаг 3: Добавьте в таблицу первичный ключ (в данном примере ключевое поле – ID):

Чтобы задать ключевое поле, в разделе Индексируемые колонки из выпадающего списка выберите нужное поле и далее нажмите на кнопку +.
Шаг 4: Сохраните созданную таблицу с помощью сочетания клавиш [Ctrl]+[S]:
Шаг 5: Заполните значения перечисления в разделе “Записи”:

Добавление записи: Нажать на кнопку “Добавить строку” и заполнить пустое поле (необходимо выделить поле левой кнопкой мыши и ввести значение) и нажать [Enter].
Удаление записи: выделите строку (щелчком левой кнопки мыши по полю записи) и нажмите [Delete].
Шаг 6: Сохраните добавленные записи с помощью сочетания клавиш [Ctrl]+[S]:

Пример создания поля со ссылкой на поле другой таблицы¶
Данный тип поля позволит хранить в таблице ссылку на другую таблицу (справочник, перечисление, список объектов, и др.).
Добавьте новую комплексную колонку в таблицу, задайте для нее Тип - Reference(Typified).
Из выпадающего списка выберите таблицу (“Ссылка на таблицу”), на которую должно ссылаться поле.

Сохраните изменения с помощью сочетания клавиш [Ctrl]+[S].
Пример создания автоинкрементной колонки¶
Данная настройка позволяет создавать автоинкрементные колонки, значения для которых определяются СУБД автоматически. Для них возможно задать начальное значение и шаг, с которым выделяются следующие значения. Если в настройках колонки эти значения не заданы, то используются значения по умолчанию (1 для начального значения и 1 для шага). Отрицательные значения шага позволяют сделать убывающий список.

Для создания автоинкрементной колонки для таблицы должны быть выполнены следующие условия:
-
Колонка должна иметь целочисленный тип;
-
Тип колонки должен быть
Not Null; -
У колонки не должно быть задано значение по умолчанию;
-
Таблица не должна иметь “Записей” в схеме данных.
Important
Для СУБД MSSQL для одной таблицы может быть создана только одна автоинкрементная колонка.
При указании настройки “Автоинкрементная колонка” или изменении ее настроек для созданной колонки с таблицей, в которой есть данные, следует учитывать, что поведение будет различно для разных СУБД:
-
MSSQL: все данные колонки затрутся и заполнятся новыми, в соответствии с настройками автоинкремента;
-
Postgres: данные колонки сохранятся, однако взятие следующего значения будет производиться с начала (начальное значение);
Important
В случае, если данная колонка использовалась как первичный ключ или по ней настроен уникальный индекс, изменение/установка автоинкремента для колонки может привести к ошибкам при добавлении значений в данную строку.
Процедуры¶
Хранимые процедуры, которые могут быть заданы в схеме для последующего использования. По сути, это обычные хранимые процедуры в БД со всеми вытекающими отличиями от функций.
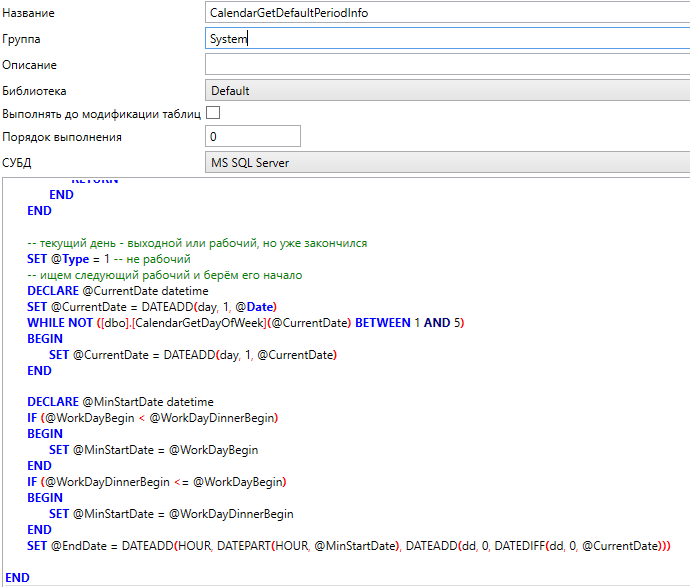
Редактор хранимых процедур имеет следующие настройки:
-
Название - название процедуры. Должно быть уникальным и совпадать с названием, указанным в запросе (см. ниже). При изменении названия в запросе, это поле автоматически заменит своё значение;
-
Группа – группа нужна для удобства работы со схемой данных (процедура будет отображаться в другой группе сразу после изменения поля);
-
Описание – описание предназначения процедуры;
-
Библиотека - библиотека, в которой будет храниться данная процедура, по умолчанию -
Default; -
Выполнять до модификации таблиц - по умолчанию запросы на создание процедур выполняются после импорта таблиц, если нужно выполнить запрос для конкретной процедуры до импорта таблиц, необходимо установить данный флаг;
-
Порядок выполнения - число, которое является сквозным для процедур, функций и миграций. Если для прочих объектов установлен порядок = 0, то создание процедуры с порядком = -1 будет выполяться перед ними, но после импорта таблиц (если не установлен соответсвующий флаг). Если порядок = 1, создание процедуры произойдёт гарантированно после объектов с более низким порядком. Создание процедур с одинаковым порядком выполняется в неопределённом порядке;
-
СУБД - селектор, который определяет редактор запроса для какой СУБД отображается в данный момент;
-
Редактор запроса - позволяет описать запрос для создания процедуры на MS SQL или Postgres, в зависимости от того, какая СУБД выбрана в селекторе СУБД в данный момент.
Функции¶
SQL функции, которые могут быть заданы в схеме для последующего использования в решении.
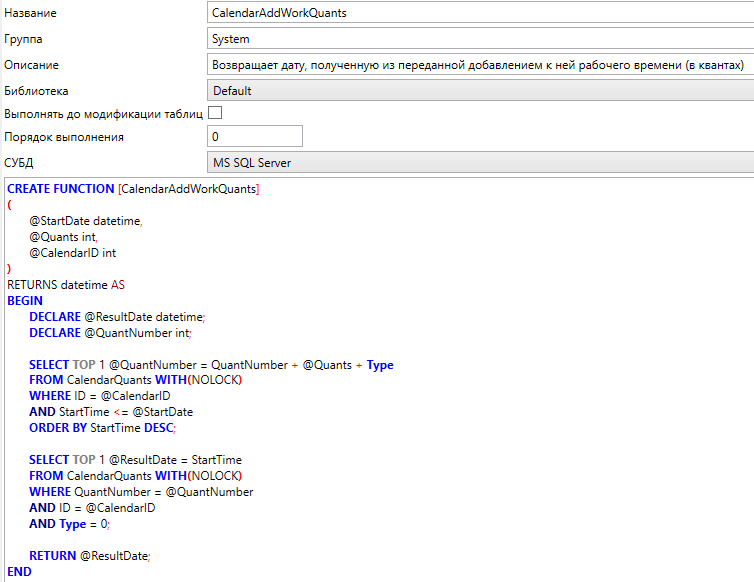
Функции так же, как и хранимые процедуры, имеют абсолютно аналогичные настройки в схеме.
-
Название - название функции. Должно быть уникальным и совпадать с названием, указанным в запросе (см. ниже). При изменении названия в запросе, это поле автоматически заменит своё значение;
-
Группа – группа нужна для удобства работы со схемой данных (функция будет отображаться в другой группе сразу после изменения поля);
-
Описание – описание предназначения функции;
-
Библиотека - библиотека, в которой будет храниться данная функция, по умолчанию -
Default; -
Выполнять до модификации таблиц - по умолчанию запросы на создание функций выполняются после импорта таблиц, если нужно выполнить запрос для конкретной функции до импорта таблиц, необходимо установить данный флаг;
-
Порядок выполнения - число, которое является сквозным для процедур, функций и миграций. Если для прочих объектов установлен порядок = 0, то функция с порядком = -1 будет выполяться перед ними, но после импорта таблиц (если не установлен соответсвующий флаг). Если порядок = 1, создание функции произойдёт гарантированно после объектов с более низким порядком. Создание функций с одинаковым порядком выполняется в неопределённом порядке;
-
СУБД - селектор, который определяет редактор запроса для какой СУБД отображается в данный момент;
-
Редактор запроса - позволяет описать запрос для создания функции на MS SQL или Postgres, в зависимости от того, какая СУБД выбрана в селекторе СУБД в данный момент.
Миграции¶
Миграции это SQL-скрипты, которые выполняются при импорте схемы один раз, а также повторно при каждом импорте, при котором SQL-текст миграции как-либо менялся.
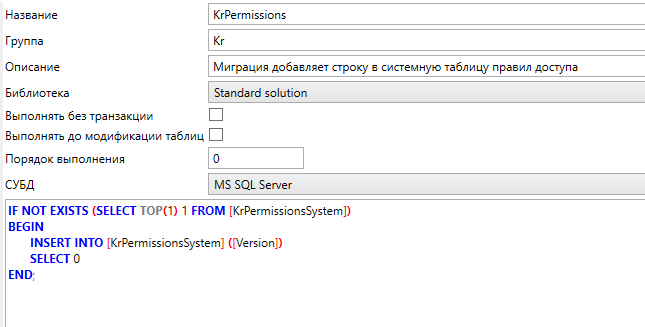
Миграции имеют схожие настройки с процедурами, но с некоторыми отличиями:
-
Название - название миграции. Никак не фигурирует в теле запроса, в отличие от процедур и функций;
-
Группа – группа нужна для удобства работы со схемой данных (миграция будет отображаться в другой группе сразу после изменения поля);
-
Описание – описание предназначения миграции;
-
Библиотека - библиотека, в которой будет храниться данная миграция, по умолчанию -
Default; -
Выполнять без транзакции - по умолчанию выполнение SQL миграции происходит внутри транзакции. Для создания типов и прочих изменений, связаных изменением структуры данных в БД, транзакцию необходимо выключить этим флагом;
-
Выполнять до модификации таблиц - по умолчанию миграции выполняются после импорта таблиц, если нужно выполнить миграцию до импорта таблиц, необходимо установить данный флаг;
-
Порядок выполнения - число, которое является сквозным для процедур, функций и миграций. Если для прочих объектов установлен порядок = 0, то миграция с порядком = -1 будет выполяться перед ними, но после импорта таблиц (если не установлен соответсвующий флаг). Если утановить порядок = 1, то выполнение миграции произойдёт гарантированно после объектов с более низким порядком. Если оставить порядок = 0, то миграция будет выполняться после импорта процедур и функций с порядком = 0. Миграции с одинаковым порядком выполняются в неопределённом порядке;
-
СУБД - селектор, который определяет редактор запроса для какой СУБД отображается в данный момент;
-
Редактор запроса - позволяет описать запрос миграции на MS SQL или Postgres, в зависимости от того, какая СУБД выбрана в селекторе СУБД в данный момент.
Создание библиотек¶
Библиотеки могут использоваться для разработки изолированных решений и далее подключаться к основной схеме данных.
Important
Для упрощения процесса обновления на новые версии платформы крайне желательно все объекты схемы данных (такие как таблицы, колонки и т.п.), добавляемые и изменяемые в рамках проектного решения, сохранять в отдельной библиотеке.
Библиотека хранится отдельно от основной схемы и описывает:
-
Новые таблицы (с колонками, ключами, индексами и записями);
-
Новые колонки в таблицах основной схемы;
-
Новые индексы в таблицах основной схемы;
-
Новые ограничения (constraints) в таблицах основной схемы;
-
Новые предопределенные строки в таблицах-перечислениях основной схемы;
-
Новые миграции;
-
Новые функции;
-
Новые процедуры.
Создать новую библиотеку можно с помощью контекстного меню на узле Библиотеки:

Для новой библиотеки указываем уникальное название и описание (при необходимости).

Далее мы можем выполнить перенос каких-либо объектов в данную библиотеку: таблицы, колонки, записи, функции и т.д.:

После внесения изменений схему данных необходимо сохранить.
Tip
Все объекты, добавляемые и изменяемые в библиотеке, сохраняются в папку с именем, соответствующим имени библиотеки. Это позволяет изолированно обновлять или переносить библиотеку между разными версиями платформы и проектными решениями.
Посмотреть все объекты схемы, относящиеся к какой-либо библиотеке можно с помощью специального фильтра, расположенного в верхней части окна. После выбора в выпадающем списке библиотеки в дереве будут отображены только те объекты, которые относятся к данной библиотеке:
